欢迎光临若泽数据,专注于数据领域的高薪人才培养!
剑指数据仓库
一、 课程概述
随着互联网技术的快速发展,海量数据现在已经进入全球经济、互联网、科学计算等诸多领域。与此同时人们对海量数据离线分析处理的需求也越来越强烈。对于海量数据的离线分析已为企业与用户创造很多的价值。本课程致力于解决目前基于Hadoop生态的海量数据离线分析的各方面在大数据场景的使用。
二、 课程目标
- 全方位掌握Hadoop/Hive架构原理以及在生产中如何使用Hadoop/Hive进行业务分析处理
- 掌握使用Hadoop和Hive在处理大数据业务分析过程中遇到的各种问题的解决和优化方案
- 掌握离线批处理通用的系统架构及处理流程,进而达到举一反三的效果,而不是为了学习知识点而学习知识点
- 掌握以Hadoop为基础的生态系统其他框架的使用;
三、 适合人群
- 打算毕业后从事找大数据工作的零基础的高校学生
- 欲转换从事大数据工作的在职人员
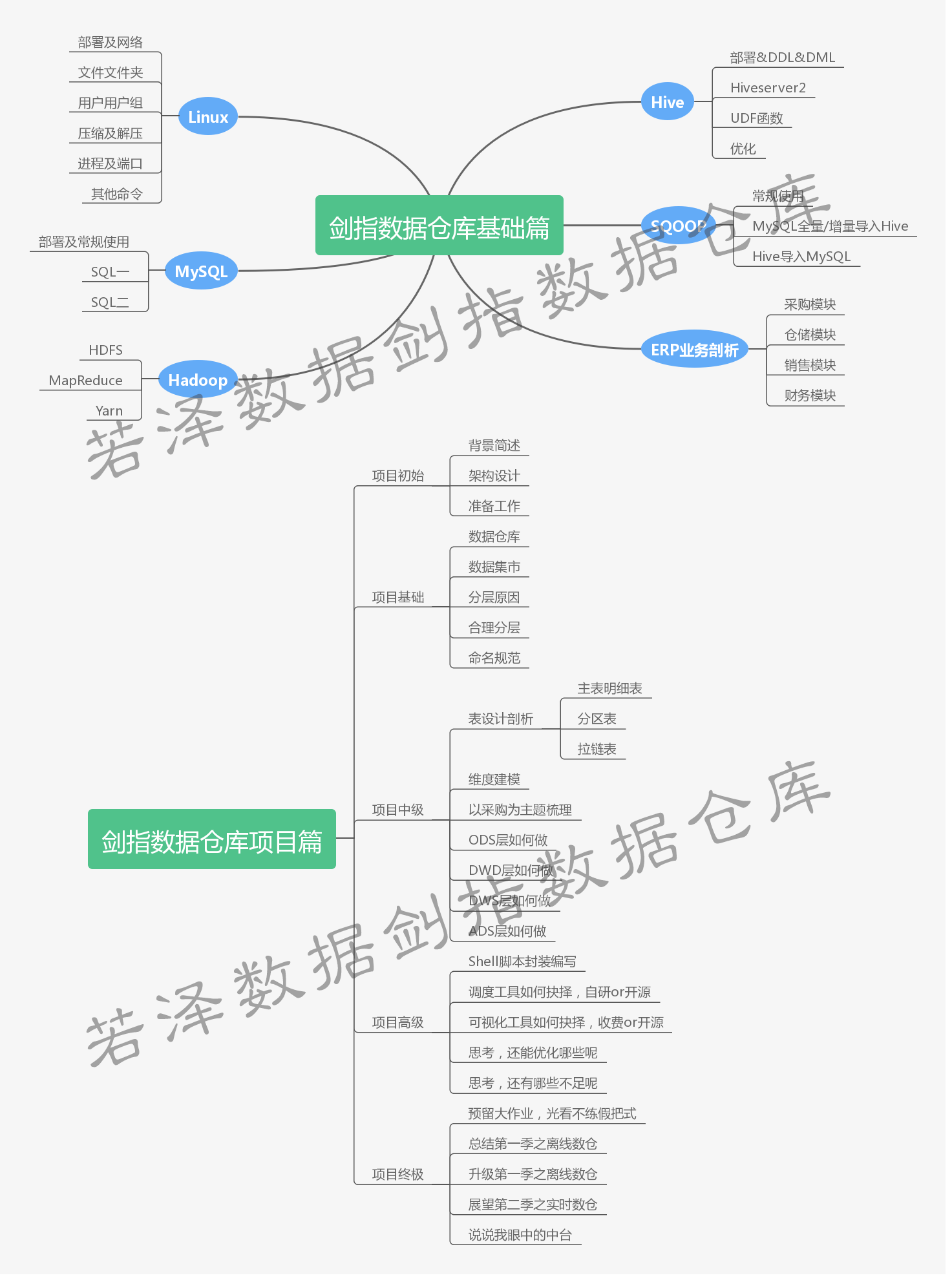
四、 课程大纲
五、 开课说明
- 讲师:若泽团队
- 授课方式:首期课程将采用实时在线直播(每周三次,每次两小时)+视频录制+在线答疑+群沟通。
- 官方课程咨询QQ:1952249535, 交流群QQ:707635769
六、 为什么选择我们
- 我们的讲师均来自于一线互联网公司架构师、高级工程师,不同于其他机构的全职老师买本书或者买其他机构的视频来讲给学生听,自己都没实战经验如何才能高质量的课程内容;
- 以实战驱动教学,课程中的项目均为讲师在公司中的真实项目/产品中抽取而来,全程代码驱动,拒绝纯理论;
- 将晦涩难懂的理论以通俗易懂的方式,并辅以案例并结合源码分析的方式讲解,让学员能够知其然并知其所以然;
- 除了大纲内容外,还有很多讲师工作经验分享不便一一列出,会在上课过程中讲解;
- 定期开展学员线下交流,扩展知识面、扩大人际圈;定期开展在线答疑;定期更新课程内容;
- 所有课程支持离线下载到本地,不受网络限制;可无限次数反复学习。

扫一扫关注小程序

扫一扫关注公众号

扫一扫联系客服星星